
 شاهین آقامعلی
شاهین آقامعلی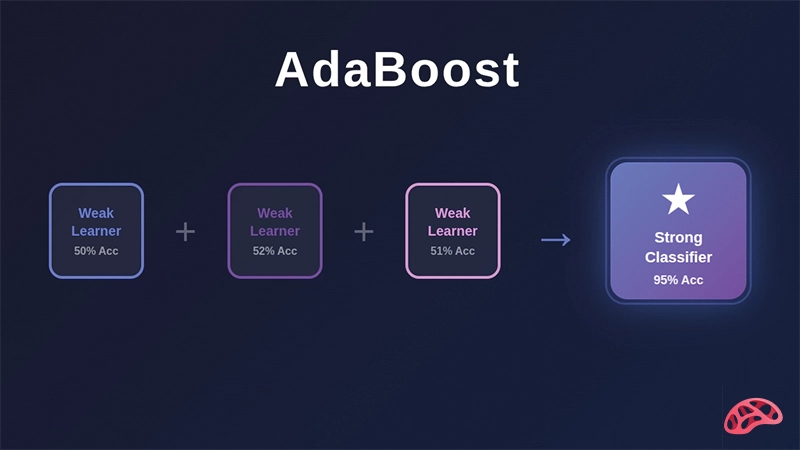
در دنیای هوش مصنوعی و یادگیری ماشین، بسیاری از مدلهای اولیه و ساده، مانند درخت تصمیم کوتاه یا طبقهبندهای خطی، نمیتوانند عملکرد قابل قبولی در پیشبینی یا طبقهبندی دادهها داشته باشند. این مدلها که به آنها مدلهای ضعیف (Weak Learners) گفته میشود، معمولاً تنها کمی بهتر از حد تصادفی عمل میکنند و در مواجهه با دادههای پیچیده دچار خطا میشوند. اما در بسیاری از کاربردهای واقعی، مانند تشخیص تقلب در تراکنشهای بانکی، شناسایی چهره، یا پیشبینی بیماریها، دقت بالای مدلها اهمیت بسیاری دارد و نمیتوان به مدلهای ضعیف بسنده کرد. اینجا جایی است که الگوریتمهای تقویتی (Boosting) وارد میشوند. ایده اصلی Boosting این است که چندین مدل ضعیف را با هم ترکیب کنیم تا یک مدل نهایی قوی و دقیق به دست آید. الگوریتمهای تقویتی با وزندهی مناسب به نمونهها و تمرکز بیشتر روی نمونههای دشوار، میتوانند دقت پیشبینی را به شکل قابل توجهی افزایش دهند.
یکی از محبوبترین الگوریتمهای تقویتی، AdaBoost است که مخفف Adaptive Boosting بوده و با ویژگی منحصر به فرد خود، بهطور پویا روی نمونههای دشوار تمرکز میکند. این ویژگی باعث میشود که مدل نهایی با تمرکز روی دادههایی که مدلهای قبلی اشتباه پیشبینی کردهاند ساخته شود و در نتیجه دقت کلی سیستم به شکل قابل توجهی افزایش یابد. به همین دلیل، AdaBoost یکی از الگوریتمهای اصلی در پروژههای یادگیری ماشین به ویژه در مسائل طبقهبندی شناخته میشود. در ادامه با آرتیجنس همراه باشید.
تاریخچه و پیدایش AdaBoost
الگوریتم AdaBoost در سال ۱۹۹۵ توسط Yoav Freund و Robert Schapire معرفی شد و به سرعت به یکی از پایههای اصلی الگوریتمهای تقویتی در یادگیری ماشین تبدیل شد. هدف اصلی Freund و Schapire ارائه روشی ساده، انعطافپذیر و مؤثر برای افزایش دقت مدلهای ضعیف (Weak Learners) بود. مدلهای ضعیف معمولاً طبقهبندهایی هستند که کمی بهتر از حد تصادفی عمل میکنند، مانند درختهای تصمیم کوتاه یا طبقهبندهای خطی ساده، و به تنهایی قادر به ارائه پیشبینیهای دقیق در مسائل پیچیده نیستند. اما AdaBoost با استفاده از یک روش هوشمندانه، این مدلها را در قالب یک چارچوب تکراری و وزنی ترکیب میکند. الگوریتم، نمونههایی را که مدلهای قبلی اشتباه پیشبینی کردهاند شناسایی کرده و وزن بیشتری به آنها اختصاص میدهد تا مدلهای بعدی تمرکز بیشتری روی آن نمونهها داشته باشند.
این رویکرد باعث میشود که چندین مدل ضعیف به یک مدل نهایی قوی و دقیق تبدیل شوند و دقت کلی پیشبینی به شکل چشمگیری افزایش یابد. معرفی AdaBoost نه تنها یک جهش مهم در زمینه Boosting بود، بلکه پایهای شد برای توسعه الگوریتمهای پیشرفتهتر مانند Gradient Boosting و XGBoost که در حال حاضر در بسیاری از پروژههای صنعتی و تحقیقاتی به کار میروند.
اصول کار AdaBoost
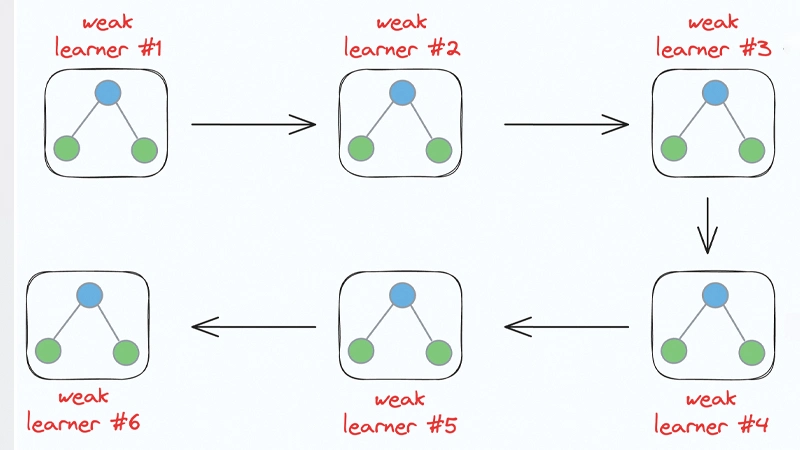
الگوریتم AdaBoost یک الگوریتم تقویتی (Boosting) است که با تمرکز بر نمونههای دشوار و ترکیب مدلهای ضعیف، عملکرد پیشبینی مدل نهایی را بهبود میبخشد. ایده اصلی این الگوریتم ساده اما بسیار مؤثر است: به جای تلاش برای ساخت یک مدل پیچیده، چندین مدل ساده و ضعیف را با یک روش هوشمندانه ترکیب میکنیم تا به دقت بالا برسیم. اصول کار AdaBoostرا میتوان در سه گام اصلی خلاصه کرد:
1. تکرار آموزش مدلهای ضعیف
در ابتدا یک مدل ضعیف (Weak Learner) انتخاب میشود، مانند یک درخت تصمیم کوتاه یا طبقهبند خطی ساده. این مدل روی دادههای آموزش آموزش داده میشود. پس از آموزش، عملکرد مدل بررسی میشود و نمونههایی که مدل اشتباه پیشبینی کرده است شناسایی میشوند. الگوریتم سپس مدل جدیدی آموزش میدهد و تمرکز بیشتری روی نمونههایی میگذارد که مدل قبلی آنها را اشتباه پیشبینی کرده است. این فرآیند چندین بار تکرار میشود تا مجموعهای از مدلهای ضعیف شکل گیرد.
2. وزندهی نمونهها
یکی از ویژگیهای کلیدی AdaBoost، وزندهی نمونهها است. هر نمونه در ابتدا وزنی برابر دارد، اما پس از هر مرحله آموزش، وزن نمونههایی که اشتباه پیشبینی شدهاند افزایش مییابد و نمونههای درست وزن کمتری میگیرند. این کار باعث میشود مدل بعدی بیشتر به نمونههای دشوار توجه کند و احتمال اشتباه در آنها کاهش یابد. این رویکرد هوشمندانه باعث میشود که الگوریتم به طور پویا روی نقاط مشکل تمرکز کند.
3. ترکیب مدلها
پس از آموزش چندین مدل ضعیف، AdaBoost آنها را با وزندهی مناسب به عملکرد هر مدل ترکیب میکند. مدلهایی که دقت بیشتری دارند وزن بالاتری در ترکیب نهایی میگیرند، و مدلهایی که عملکرد ضعیفتری دارند وزن کمتری دارند. نتیجه این فرآیند، یک مدل نهایی قوی، دقیق و مقاومتر نسبت به مدلهای ضعیف اولیه است که میتواند دادههای پیچیده را با دقت بیشتری پیشبینی کند.
گامهای اجرای الگوریتم AdaBoost
اجرای الگوریتم AdaBoost یک فرآیند مرحلهبهمرحله است که از آمادهسازی دادهها تا ترکیب مدلهای ضعیف برای ایجاد مدل نهایی قدرتمند ادامه دارد. این مراحل به ترتیب زیر انجام میشوند:
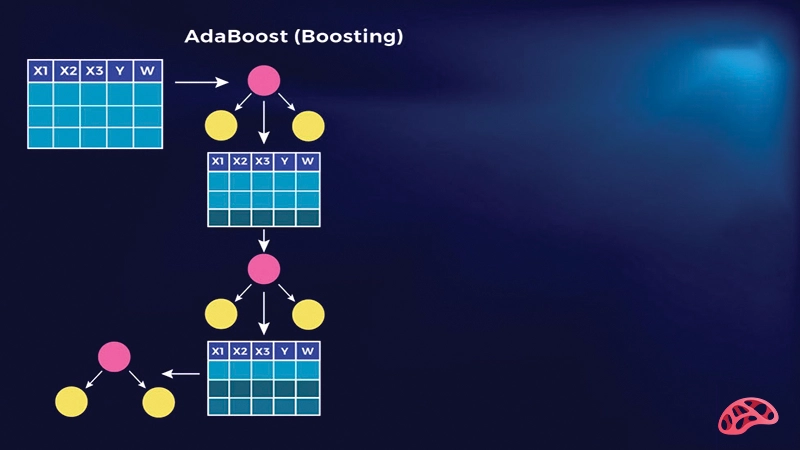
1. آمادهسازی دادهها
اولین گام در اجرای AdaBoost، آمادهسازی مجموعه دادههاست. دادهها معمولاً به دو بخش آموزش و تست تقسیم میشوند تا بتوان عملکرد مدل نهایی را ارزیابی کرد. علاوه بر این، به هر نمونه در ابتدا یک وزن اولیه برابر اختصاص داده میشود تا الگوریتم بتواند در مراحل بعدی وزنها را تغییر دهد. این وزندهی اولیه اساس تمرکز الگوریتم روی نمونهها در مراحل بعدی است.
2. آموزش مدل ضعیف
در این مرحله، یک مدل ضعیف (Weak Learner) انتخاب و آموزش داده میشود. مدلهای ضعیف معمولاً ساده هستند، مانند درخت تصمیم یک سطحی یا طبقهبندهای خطی ساده. هنگام آموزش، وزن نمونهها در نظر گرفته میشود تا مدل بتواند بهتر نمونههایی که اهمیت بیشتری دارند را یاد بگیرد.
3. ارزیابی و وزندهی
پس از آموزش مدل ضعیف، خطای مدل محاسبه میشود و نمونههایی که اشتباه پیشبینی شدهاند شناسایی میشوند. این نمونهها وزن بیشتری دریافت میکنند تا مدل بعدی روی آنها تمرکز بیشتری داشته باشد. نمونههایی که درست پیشبینی شدهاند، وزن کمتری میگیرند. این فرآیند باعث میشود که مدلهای بعدی توجه خود را روی نقاط دشوار داده معطوف کنند و عملکرد کل سیستم بهبود یابد.
4. تکرار مراحل
مراحل آموزش مدل ضعیف و وزندهی نمونهها چندین بار تکرار میشوند. هر بار، یک مدل ضعیف جدید با توجه به وزنهای بهروزشده آموزش داده میشود و مجموعهای از مدلهای ضعیف ایجاد میشود. این تکرار باعث میشود که هر مدل جدید، اشتباهات مدل قبلی را جبران کند و به تدریج مدل نهایی قویتر شود.
5. ترکیب مدلها
در نهایت، همه مدلهای ضعیف ایجاد شده با وزندهی مناسب ترکیب میشوند. مدلهایی که دقت بالاتری دارند، وزن بیشتری در ترکیب نهایی میگیرند و مدلهایی که ضعیفتر عمل کردهاند، وزن کمتری دارند. نتیجه این فرآیند، یک مدل نهایی قدرتمند و دقیق است که دقت بسیار بالاتری نسبت به هر مدل ضعیف جداگانه دارد و میتواند دادههای پیچیده را با کیفیت بهتری پیشبینی کند.
مزایای استفاده از AdaBoost
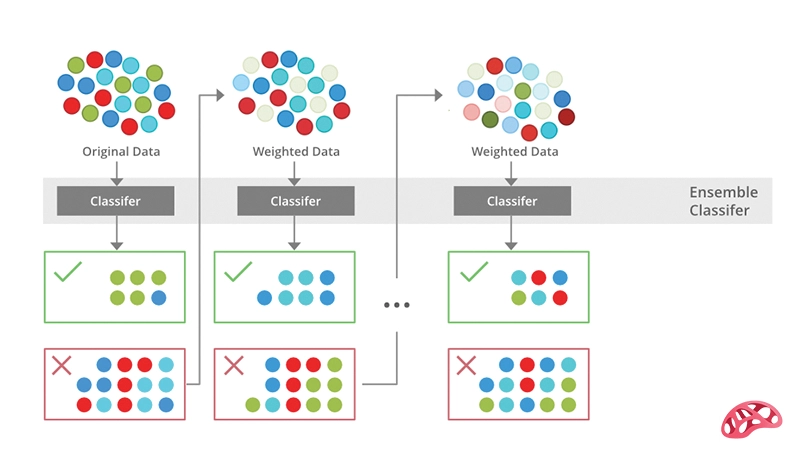
الگوریتم AdaBoost یکی از محبوبترین روشهای تقویتی در یادگیری ماشین است و دلایل متعددی برای استفاده از آن وجود دارد. مزایای اصلی این الگوریتم عبارتند از:
1. بهبود دقت مدلها
یکی از مهمترین مزایای AdaBoost، توانایی آن در تبدیل مدلهای ضعیف به مدلهای قوی است. حتی اگر مدل اولیه عملکرد کمی بهتر از حد تصادفی داشته باشد، AdaBoost با ترکیب چندین مدل ضعیف و تمرکز روی نمونههای مشکلدار، دقت پیشبینی را به شکل قابل توجهی افزایش میدهد. این ویژگی باعث میشود AdaBoostدر پروژههایی که دقت اهمیت بالایی دارد، انتخابی مناسب باشد.
2. ساده و انعطافپذیر
AdaBoost یک الگوریتم ساده و در عین حال انعطافپذیر است. این الگوریتم میتواند با انواع مختلف مدلهای ضعیف کار کند، مانند درخت تصمیم کوتاه، طبقهبندهای خطی یا حتی مدلهای دیگر. انعطافپذیری AdaBoost باعث میشود که به راحتی در مسائل متنوع طبقهبندی و پیشبینی قابل استفاده باشد.
3. عدم نیاز به تنظیمات پیچیده
یکی دیگر از مزایای مهم AdaBoost این است که به تنظیمات پیچیده زیادی نیاز ندارد. الگوریتم به طور خودکار وزن نمونهها و مدلها را تنظیم میکند و نیازی به تنظیم دستی پارامترهای پیچیده ندارد. این ویژگی باعث میشود که حتی توسعهدهندگان تازهکار بتوانند به راحتی از AdaBoost استفاده کنند و مدلهای دقیق بسازند.
4. تمرکز بر نمونههای دشوار
AdaBoost به طور خاص روی نمونههایی که مدلهای قبلی اشتباه پیشبینی کردهاند تمرکز میکند. این تمرکز باعث میشود که مدل نهایی، عملکرد بهتری روی دادههای مشکلدار داشته باشد و از اشتباهات مکرر جلوگیری کند. در نتیجه، الگوریتم نسبت به دادههای نامتوازن و پیچیده مقاومتر است و پیشبینی دقیقتری ارائه میدهد.
معایب AdaBoost
اگرچه AdaBoost یک الگوریتم قدرتمند و مؤثر در یادگیری ماشین است، اما محدودیتها و معایبی نیز دارد که باید قبل از استفاده از آن در پروژهها مورد توجه قرار گیرند:
1. حساسیت به دادههای نویزی
یکی از بزرگترین چالشهای AdaBoost، حساسیت آن به دادههای نویزی است. اگر مجموعه داده شامل نمونههای اشتباه یا نویز زیادی باشد، الگوریتم به طور بیش از حد روی این دادهها تمرکز میکند و سعی میکند آنها را اصلاح کند. این امر میتواند منجر به کاهش دقت کلی مدل و Overfitting شود، یعنی مدل یاد میگیرد نویز را هم به عنوان الگو در نظر بگیرد.
2. نیاز به محاسبات زیاد
AdaBoost با تکرار آموزش مدلهای ضعیف و وزندهی نمونهها، نیاز به محاسبات زیادی دارد. با افزایش تعداد مدلهای ضعیف، زمان آموزش و ترکیب مدلها بیشتر میشود و ممکن است پردازش دادههای بزرگ یا پیچیده کند شود. بنابراین، در پروژههایی با دادههای بسیار حجیم یا زمان محدود، باید این موضوع را مدنظر قرار داد.
3. عدم تحمل مدلهای ضعیف خیلی ضعیف
AdaBoost برای عملکرد صحیح نیاز دارد که مدل پایه یا مدل ضعیف اولیه کمی بهتر از حد تصادفی باشد. اگر مدل پایه بسیار ضعیف باشد، الگوریتم نمیتواند خطاها را جبران کند و مدل نهایی دقت قابل قبولی نخواهد داشت. بنابراین انتخاب مدل ضعیف مناسب قبل از اجرای AdaBoost، یکی از مراحل حیاتی است.
کاربردهای AdaBoost
الگوریتم AdaBoost به دلیل قدرت خود در ترکیب مدلهای ضعیف و تمرکز روی نمونههای دشوار، در بسیاری از حوزههای عملی یادگیری ماشین کاربرد دارد. برخی از مهمترین کاربردهای آن عبارتند از:
1. طبقهبندی متن
AdaBoost در پردازش زبان طبیعی (NLP) بسیار کاربردی است، به ویژه برای تشخیص ایمیلهای اسپم و دستهبندی اخبار یا مقالات. الگوریتم با تمرکز روی نمونههای دشوار و اشتباه، دقت بالایی در تشخیص نوع متن و جلوگیری از خطاهای طبقهبندی دارد.
2. تشخیص چهره
یکی از مشهورترین کاربردهای AdaBoost در سیستمهای شناسایی چهره است. این الگوریتم میتواند ویژگیهای مهم چهره را از تصویر استخراج کند و با ترکیب چندین مدل ضعیف، دقت تشخیص چهره را به شکل چشمگیری افزایش دهد. سیستمهای امنیتی و برنامههای موبایل از این روش برای شناسایی سریع و دقیق افراد استفاده میکنند.
3. پزشکی و سلامت
در حوزه پزشکی، AdaBoostبرای پیشبینی بیماریها، تشخیص ناهنجاریها و تحلیل دادههای پزشکی کاربرد دارد. الگوریتم با تمرکز روی نمونههای غیرمعمول یا دشوار، میتواند به پزشکان کمک کند تا تشخیص دقیقتر و سریعتری ارائه دهند، به ویژه در سیستمهای هوش مصنوعی پزشکی که نیاز به تصمیمگیری مطمئن دارند.
4. سیستمهای تشخیص تقلب
در بانکداری و امور مالی، AdaBoost برای شناسایی تراکنشهای مشکوک و جلوگیری از تقلب استفاده میشود. الگوریتم با تمرکز روی نمونههای غیرمعمول یا تراکنشهایی که مدلهای اولیه اشتباه پیشبینی کردهاند، میتواند به کاهش خطا و افزایش امنیت سیستم کمک کند.
مقایسه AdaBoost با سایر الگوریتمهای Ensemble
برای درک بهتر مزایا و محدودیتهای AdaBoost، آن را با دیگر الگوریتمهای Ensemble مانند Random Forest و Gradient Boosting مقایسه میکنیم:
| الگوریتم | روش ترکیب مدلها | حساسیت به نویز | پیچیدگی محاسباتی | دقت در دادههای نامتوازن |
|---|---|---|---|---|
| AdaBoost | وزندهی مدلهای ضعیف و جمع وزنی | بالا | متوسط | متوسط |
| Random Forest | رایگیری اکثریت مدلها | پایین | متوسط | بالا |
| Gradient Boosting | کاهش گرادیان خطا و وزندهی مدلها | متوسط | بالا | بالا |
این جدول نشان میدهد که AdaBoost الگوریتمی سریع و ساده است که دقت خوبی روی دادههای کم نویز دارد، اما در مقایسه با Gradient Boosting و Random Forest در برابر نویز حساستر است.
نتیجهگیری:
الگوریتم AdaBoostیکی از سادهترین و مؤثرترین روشهای تقویتی در یادگیری ماشین است. با استفاده از مدلهای ضعیف و تمرکز روی نمونههای دشوار، میتوان مدلهای قدرتمندی ایجاد کرد که دقت بالایی در پیشبینی داشته باشند. با این حال، حساسیت به دادههای نویزی و نیاز به انتخاب مدل ضعیف مناسب، از چالشهای اصلی آن است. استفاده صحیح از AdaBoost در پروژههای طبقهبندی و پیشبینی میتواند باعث افزایش چشمگیر دقت شود و به توسعهدهندگان یادگیری ماشین ابزار قدرتمندی ارائه دهد.
منبع مقاله:




پاسخ :